
 Лекция 1. Константы. Метки. Простые типы данных: Char.
Лекция 1. Константы. Метки. Простые типы данных: Char.
Программа на Паскале - это текст, который обрабатывается компилятором. Он распознает в тексте разделители и лексемы, а среди лексем - понятные ему слова.
Принцип компилятора: всякий придуманный пользователем идентификатор ДОЛЖЕН БЫТЬ ОПИСАН прежде, чем будет использоваться. Вот пример описания из нашей первой программы:
Var a,b,c,diskr,x1,x2: real;
Прочитав лексему (слово) Var компилятор подготовлен прочесть список
идентификаторов (разделитель в списке - запятая). Читает a,b,c,diskr,x1,x2 затем видит двоеточие. Это для него означает, что дальше будет идентификатор типа данных для этого списка. Слово real ему понятно.
Программа должна иметь установленную структуру (ссылка показывает структуру простейшей программы).
Рассмотрим описание констант в программе, вычисляющей время свободного падения с заданной высоты:
Program Primer2;
Const Uskor_G = 9.81; {Ускорение свободного падения, м/сек}
Messa = 'Время падения = '; {Приготовил текст для вывода ответа}
Var hh: Real;
begin
write('Введите высоту (метр)--> ');readln(hh);
writeln(Messa,sqrt(2*hh/uskor_g):0:2, {:2 - с точностью до сотых}
' сек');
readln;
end.
Результат работы (Free Pascal):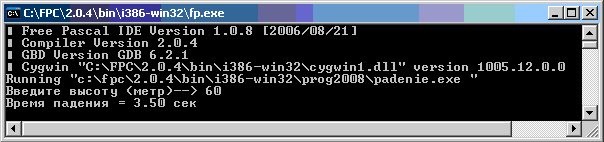
Так что синтаксис описания константы:
const <имя(идентификатор) константы> = <значение>;
Примеры констант разных типов:
Вещественные числа:
Const X=0.5; Z=-1e-5; {Z=-0.00001} W=7.5E+15;
Строки:
Const Simbols='TURBO'; TwoLines='Line1'#13#10'Line2;
{#13#10 - символы с кодировками 13 и 10 - переход
на новую строку, так что здесь 2 строки}
Константы-множества:
Latin1 = ['A'..'Z']; ABC= ["A','B','C'];
Ten= [0..9];>
Если идентификатор связывает нас с одним значением, то такой тип данных относится к ПРОСТЫМ типам. Например, hh - высота с которой что-то падает равна, например 60м. Кроме целых и вещественных чисел есть другие простые типы.
Символьные типы.
В Паскале один такой тип - char. Переменные этого типа хранят символы: буквы, цифры,~ % # и т п., всего 256 символов. Символы кодируются числами в диапазоне 0..255, то есть числами типа byte. Для хранения каждой переменной выделяется 1 байт памяти. Кодировкам 0..31 соответствуют управляющие символы, например, для принтера. Коды 32..127 используются для латинских букв и др. символов. Национальные буквы кодируются числами > 127, для каждого языка - своя кодовая страница. Это - кодировка ASCII.
В Делфи 2 символьных типа: AnsiChar и WideChar, причем WideChar занимает 2 байта, следовательно, может иметь 256*256 различных значений и используется для кодировки UniCode, которая не требует отдельных страниц для каждого языка.
Используя ФУНКЦИЮ Chr(n) и вводя число n с клавиатуры, Вы можете увидеть соответствующий символ. И наоборот, вводя символ, и используя функцию ord() узнать его кодировку. Пример программы:
Program Simv1;
var sim: char; kod: byte;
begin
write('Введите символ --> '); readln(sim);
writeln ('Код символа ',sim, ' = ',ord(sim));
write('Введите код (0..255) --> '); readln(kod);
writeln('Коду ',kod,' соответствует символ: ',Chr(kod));
readln;
end.
Чтобы программа работала многократно, используем ОПЕРАТОР goto <метка> и метку.
Метка описывается так:
label <метка>; где <метка> - <идентификатор>;
Когда программа при исполнении дойдет до оператора goto <метка>, она перейдет к выполнению оператора, перед которым стоит эта метка (справа от метки ставят двоеточие).
Исправленная программа:
Program Simv1;
var sim: char; kod: byte;
label idi_suda;
begin
idi_suda: write('Введите символ --> ');
readln(sim);
writeln ('Код символа ',sim, ' = ',ord(sim));
write('Введите код (0..255) --> '); readln(kod);
writeln('Коду ',kod,' соответствует символ: ',Chr(kod));
readln;
goto idi_suda;
end.
Программа работает, но как из нее выходить? Можно закрывать окно крестиком, но это - не дело. Пусть программа идет на повторение только если введен код не равный нулю. Чтобы реализовать эту идею, нужно использовать ОПЕРАТОР if (если). Исправленная чуть-чуть программа :
Program Simv1;
var sim: char; kod: byte;
label idi_suda;
begin
idi_suda: write('Введите символ --> ');
readln(sim);
writeln ('Код символа ',sim, ' = ',ord(sim));
write('Введите код (0..255) --> '); readln(kod);
writeln('Коду ',kod,' соответствует символ: ',Chr(kod));
readln;
if kod <> 0 then goto idi_suda;
end.
Для преобразования типов данных мне больше нравится УНИВЕРСАЛЬНЫЙ способ, синтасис которого:
<новый тип>(<значение>). Так что вместо ord(sim) можно использовать byte(sim), а вместо chr(kod) - char(kod); Этот способ работает, если преобразование имеет смысл.
Описание типов.
Итак, в языке Паскаль есть стандартные (предопределенные) типы, то есть типы, которые описывать не надо. Например, Char - символьный тип, с которым мы только что познакомились.Вместе с тем, иногда есть необходимость использовать собственные типы. Например, в какой-то программе обрабатываются только заглавные латинские буквы. Так что если вдруг появляется (например, при вводе) какой-то иной символ - это признак ошибки.
В данном случае нужно применить интервальный тип, который описывается (например) так:
type lat = 'A'..'Z';
Далее можно описывать переменные этого типа:
var bukv1,bukv2: lat;
То есть переменные описываются как бы в 2 этапа: сначала тип, затем переменные. Однако в Паскале возможно описание переменных без описания типа. Например:
var bukv1,bukv2:'A'..'Z';
Так что новые, "самодельные" типы можно отдельно не описывать (в смысле - не определять идентификатор типа). Но есть исключение: при описании ПАРАМЕТРОВ подпрограмм (см лекция 5) обязательно требуется, чтобы типы параметров были иденификаторами, т е были описаны ранее в главной программе.
![]()